Nội dung toàn văn Tiêu chuẩn quốc gia TCVN 12293:2014 (ISO/TR 16705:2016) về Phương pháp thống kê áp dụng cho six sigma - Các ví dụ minh họa phân tích bảng chéo
TIÊU CHUẨN QUỐC GIA
TCVN 12293:2014
ISO/TR 16705:2016
PHƯƠNG PHÁP THỐNG KÊ ÁP DỤNG CHO SIX SIGMA - CÁC VÍ DỤ MINH HỌA PHÂN TÍCH BẢNG CHÉO
Statistical methods for implementation of Six Sigma - Selected illustrations of contingency table analysis
Lời nói dầu
TCVN 12293:2018 hoàn toàn tương dương với ISO/TR 16705:2016.
TCVN 12293:2018 do Ban kỹ thuật tiêu chuẩn quốc gia TCVN/TC 69 Ứng dụng các phương pháp thống kê biên soạn, Tổng cục Tiêu chuẩn Đo lường Chất lượng đề nghị, Bộ Khoa học và Công nghệ công bố.
Lời giới thiệu
Cộng đồng Six Sigma và các cộng đồng tiêu chuẩn thống kê quốc tế chia sẻ quan điểm về cải tiến liên tục và nhiều công cụ phân tích. Cộng đồng Six Sigma có xu hướng chấp nhận cách tiếp cận thực tế do hạn chế thời gian và nguồn lực. Cộng đồng tiêu chuẩn thống kê hướng đến các tài liệu chặt chẽ đạt được bằng sự đồng thuận quốc tế dài hạn. Sự chênh lệch về áp lực thời gian, sự chính xác về mặt toán học và sử dụng phần mềm thống kê đã ngăn cản sự trao đổi, sự đồng vận và sự đánh giá lẫn nhau giữa hai nhóm.
Tiêu chuẩn này lấy một công cụ thống kê cụ thể (phân tích bảng chéo), xây dựng chủ đề một cách tổng quát (theo tinh thần của tiêu chuẩn), sau đó minh họa nó thông qua việc sử dụng một số ứng dụng chi tiết và khác biệt. Mô tả chung tập trung vào sự tương đồng qua các nghiên cứu được thiết kế để đánh giá mối quan hệ các biến phân loại.
Các phụ lục bao gồm các hình minh họa không chỉ theo khung cơ bản, mà còn xác định sắc thái và nét riêng biệt trong các ứng dụng cụ thể. Mỗi ví dụ số cung cấp ít nhất một ‘giải pháp’ cho vấn đề, mà thường là trường hợp đối với Six Sigma thực tế và các ứng dụng lĩnh vực khác.
PHƯƠNG PHÁP THỐNG KÊ ÁP DỤNG CHO SIX SIGMA - CÁC VÍ DỤ MINH HỌA PHÂN TÍCH BẢNG CHÉO
Statistical methods for implementation of Six Sigma - Selected illustrations of contingency table analysis
1 Phạm vi áp dụng
Tiêu chuẩn mô tả các bước cần thiết cho phân tích bảng chéo và phương pháp để phân tích mối quan hệ giữa các biến phân loại (bao gồm cả biến danh nghĩa và biến thứ tự).
Tiêu chuẩn này đưa ra các ví dụ về phân tích bảng chéo. Các ví dụ minh họa từ các lĩnh vực khác nhau có nhấn mạnh sự khác nhau gợi ý các quy trình phân tích bảng chéo bằng cách sử dụng các ứng dụng phần mềm khác nhau.
Trong tiêu chuẩn này, chỉ xem xét bảng chéo hai chiều.
2 Tài liệu viện dẫn
Trong tiêu chuẩn này không có tài liệu nào được viện dẫn.
3 Thuật ngữ và định nghĩa
Tiêu chuẩn này sử dụng các thuật ngữ, định nghĩa trong TCVN 8244-1 (ISO 3534-1), TCVN 8244-2 (ISO 3534-2) và các thuật ngữ, định nghĩa dưới đây.
3.1
Biến phân loại (categorical variable)
Biến với thang đo bao gồm tập hợp nhiều loại.
3.2
Dữ liệu danh nghĩa (nominal data)
Biến với một thang đo danh nghĩa.
[NGUỒN: TCVN 8244-2:2010 (ISO 3534-2:2006), 1.1.6]
3.3
Dữ liệu thứ tự (ordinal data)
Biến với một thang đo thứ tự.
[NGUỒN: TCVN 8244-2:2010 (ISO 3534-2:2006), 1.1.7]
3.4
Bảng chéo (contingency table)
Biểu diễn dữ liệu phản loại bằng bảng, cho thấy tần số tổ hợp cụ thể các giá trị của hai hay nhiều biến ngẫu nhiên rời rạc.
CHÚ THÍCH 1: Bảng có hai biến phân loại chéo được gọi là “bảng chéo hai chiều”, bảng có ba biến phân loại chéo được gọi là “bảng chéo ba chiều”. Bảng hai chiều có r hàng và c cột còn được gọi là ‘bảng r x c”.
VÍ DỤ: Cho các cá thể n được phân loại theo các biến phân loại X và Y với các mức tương ứng X1, X2 và Y1, Y2. Số cá thể với cả hai thuộc tính Xi và Yi là nij. Khi đó có bảng 2 x 2 như sau đây.
Bảng 1 - Bảng chéo 2 x 2
Biến X | Biến Y | |
Y1 | Y2 | |
X1 | n11 | n12 |
X2 | n12 | n22 |
3.5
p-giá trị (p-value)
Xác suất quan trắc thấy giá trị thống kê kiểm nghiệm được quan trắc hoặc giá trị khác nào đó lớn hơn giá trị tới hạn để bác bỏ giả thuyết không.
[NGUỒN: TCVN 8244-1:2010 (ISO 3534-1:2006), 1.49]
4 Ký hiệu và chữ viết tắt
H0 | giả thuyết không |
Ha | đối giả thuyết |
c2 | thống kê Khi bình phương |
G2 | thống kê tỷ số hợp lý |
n | tổng số ô |
bảng r x c | bảng chéo với r hàng và c cột |
DF | bậc tự đo |
5 Mô tả chung về phân tích bảng chéo
5.1 Tổng quan về cấu trúc phân tích bảng chéo
Tiêu chuẩn này đưa ra hướng dẫn chung về thiết kế, tiến hành và phân tích về phân tích bảng chéo và minh họa các bước với các ứng dụng khác nhau được cho trong Phụ lục A đến Phụ lục D. Mỗi một ví dụ theo cấu trúc cơ bản được cho trong Bảng 2.
Bảng 2 - Các bước cơ bản cho phân tích bảng chéo
1 | Nêu mục tiêu tổng thể |
2 | Liệt kê các thuộc tính quan tâm |
3 | Nêu giả thuyết không |
4 | Phương án lấy mẫu |
5 | Xử lý và phân tích dữ liệu |
6 | Chấp nhận hoặc bác bỏ giả thuyết không (Kết luận) |
Sử dụng phân tích bảng chéo để đánh giá mối liên hệ của hai hay nhiều biến phân loại. Tiêu chuẩn này tập trung vào phân tích bảng chéo hai chiều, chi xem xét mối quan hệ của hai biến phân loại. Trong tiêu chuẩn này không có các phương pháp phân tích cụ thể cho ba hoặc nhiều biến phân loại. Các bước cho trong Bảng 2 cung cấp các kỹ thuật và quy trình chung cho phân tích bảng chéo. Mỗi một bước trong sáu bước được giải thích khái quát trong các điều từ 5.2 đến 5.7.
5.2 Mục tiêu tổng thể của phân tích bảng chéo
Phân tích bảng chéo có thể được sử dụng trong các dự án Six Sigma1) trong giai đoạn ‘Phân tích’ của phương pháp luận DMAIC và thường được sử dụng trong khảo sát lấy mẫu, khoa học xã hội và nghiên cứu y học,... Ngoài các phương pháp thống kê thông thường tập trung vào các biến liên tục, phân tích bảng chéo chủ yếu xử lý dữ liệu phân loại, bao gồm dữ liệu danh nghĩa và dữ liệu thứ tự. Trong trường hợp giá trị được quan trắc là tần số liên kết nhất định của một số điều kiện mục tiêu, nhưng không phải là giá trị liên tục từ thiết bị thì phân tích bảng chéo là cần thiết.
Động lực chính của phương pháp này là để kiểm nghiệm mối liên hệ các biến phân loại, bao gồm các tình huống sau:
a) để đánh giá xem phân bố tần số quan trắc có khác với phân bố lý thuyết không;
b) để đánh giá tính độc lập của hai biến phân loại;
c) để đánh giá tính thuần nhất của một số phân bố cùng loại;
d) để đánh giá mối liên hệ xu hướng của các quan trắc về các biến thứ tự;
e) để đánh giá mối liên hệ rộng rãi giữa các mức của biến phân loại.
5.3 Liệt kê thuộc tính quan tâm
Tiêu chuẩn này xem xét mối liên hệ của hai biến phân loại dựa trên tần số được quan trắc của đặc trưng tương ứng với sự kết hợp các mức khác nhau của thuộc tính quan tâm.
Nếu mối liên hệ giữa biến định lượng và biến phân loại được quan tâm (ví dụ: cỡ cốc so với trang trí bề mặt), thì cần phân chia dữ liệu định lượng thành các lớp thứ tự (ví dụ, nhỏ, trung bình, lớn).
5.4 Nêu giả thuyết không
Tiêu chuẩn này xác định xem biến hàng và biến cột có độc lập hay không. Giả thuyết không đối với kiểm nghiệm Khi bình phương là
H0: biến hàng và biến cột độc lập;
và đối giả thuyết là
Ha: biến hàng và biến cột không độc lập.
5.5 Phương án lấy mẫu
Trong phương án lấy mẫu đối với phân tích bảng chéo, các biến và các mức cần được xác định trước tiên. Đối với bảng chéo hai chiều, có bốn phương án lấy mẫu có thể để tạo thành các bảng.
a) Tổng số ô n không cố định.
b) Tổng số ô n cố định, nhưng tổng số hàng và cột không cố định.
c) Tổng số ô n cố định, và tổng biên hàng hoặc tổng biên cột cố định;
d) Tổng số ô n cố định và cả tổng biên hàng và tổng biên cột cố định.
Bốn phương án lấy mẫu nối trên tương ứng với các mục đích khác nhau của phân tích dữ liệu phân loại. Trường hợp a) là lấy mẫu ngẫu nhiên, tất cả số tần số là độc lập. Ví dụ, số khách hàng vào siêu thị trong ngày là biến ngẫu nhiên. Khách hàng được chia thành bốn nhóm dựa trên giới tính của họ và liệu họ có đang mua sắm hay không (nam/mua sắm, nam/không mua sắm, nữ/mua sắm, nữ/không mua sắm). Các nhóm bốn số này tạo thành một bảng chéo. Trường hợp b) áp dụng được với khảo sát lấy mẫu khi cỡ mẫu cố định. Trường hợp c) thường là phân tích về phân tích so sánh. Ví dụ, khi tiến hành nghiên cứu mối liên hệ giữa ung thư phổi và hút thuốc, nhóm bệnh nhân bị ung thư phổi và nhóm người khỏe mạnh với cùng độ tuổi, giới tính và điều kiện thể chất khác được lựa chọn để nghiên cứu. Tổng số người trong mỗi nhóm là cố định. Trường hợp d) là một kiểm nghiệm khác của phân tích tương đồng định tính, thường được sử dụng để kiểm nghiệm xem các kết quả từ hai hệ thống đo có nhất quán với nhau không. Đối với phân tích tương đồng định tính, có thể tham khảo ISO14468. Các thống kê tính toán của kiểm nghiệm tính độc lập đối với ba trường hợp đầu tiên là giống nhau.
Ngẫu nhiên hóa rất quan trọng khi lấy mẫu thực nghiệm. Các quan trắc trong từng ô được thực hiện trên một mẫu ngẫu nhiên. Khi không thuận tiện hoặc khó để có được các mẫu đầy đủ, thì cần phải chú ý đến mọi yếu tố gây nhiễu có thể ảnh hưởng đến kết quả phân tích.
Bảng 3 trình bày bảng chéo hai chiều với r mức của biến X và c mức của biến Y. Tần số quan trắc của mỗi tổ hợp hai biến là nij (i = 1,…, r, j = 1, …, c).
Bảng 3 - Bố trí phân tích bảng chéo r x c tổng quát
Biến X | Biến Y | |||
Y1 | Y2 | … | Yc | |
X1 | n11 | n12 | … | n1c |
X2 | n21 | n22 | … | n2c |
… | … | … | … | … |
Xr | nr1 | nr2 | … | nrc |
5.6 Xử lý và phân tích dữ liệu
5.6.1 Kiểm nghiệm Khi bình phương
Kiểm nghiệm Khi bình phương (c2) là công cụ cơ bản nhất cho phân tích bảng chéo để kiểm nghiệm tính độc lập của các biến. Nó thường được sử dụng để so sánh dữ liệu được quan trắc với dữ liệu mong muốn nào đó theo mục tiêu kiểm nghiệm cụ thể.
Đối với bảng chéo một chiều, chỉ có một biến phân loại với hai hoặc nhiều mức, kiểm nghiệm Khi bình phương thường được gọi là “kiểm nghiệm sự phù hợp” có thể được sử dụng để đánh giá liệu dữ liệu được quan trắc phân loại theo các mức có tuân theo phân bố lý thuyết hay không.
Đối với bảng chéo hai chiều, bảng r x c, kiểm nghiệm Khi bình phương có thể được sử dụng để đánh giá xem hai biến phân loại có độc lập hay không. Nó có thể kiểm nghiệm tính thuần nhất của các phân bố cùng loại, mà cũng được gọi là “kiểm nghiệm tính thuần nhất”.
Kiểm nghiệm Khi bình phương được xác định để đánh giá khoảng cách của dữ liệu quan trắc so với dữ liệu mong muốn. Công thức để tính thống kê Khi bình phương là:
| (1) |
trong đó
o là dữ liệu tần số quan trắc;
e là dữ liệu tần số mong muốn.
Công thức là tổng của bình phương chênh lệch giữa tần số quan trắc và tần số mong muốn, được chia cho tần số mong muốn trong tất cả các ô.
Đối với bảng r x c, biến hàng X có r mức và biến cột Y có c mức. Với giả thuyết không H0, X và Y độc lập và đối giả thuyết Hα, X và Y không độc lập, thống kê Khi bình phương được tính như sau:
| (2) |
trong đó
nij là tần số quan trắc trong mức thứ i của biến hàng X và mức thứ j của biến cột Y;
mij là giá trị mong muốn của nij giả định độc lập.
Thống kê này có giá trị nhỏ nhất bằng không khi tất cả nij = mij. Đối với cỡ mẫu cố định, chênh lệch lớn hơn giữa nij và mij đem lại giá trị c2 lớn hơn và bằng chứng rõ ràng hơn chống lại H0. Thống kê c2 theo phân bố tiệm cận Khi bình phương khi n lớn, với bậc tự do (DF) = (r-1)(c-1). Bác bỏ giả thuyết không nếu p-giá trị nhỏ hơn giá trị quy định trước, thường được lấy là 0,05. Xấp xỉ Khi bình phương được cải thiện khi mij tăng. Chú ý là khi bất kỳ giá trị mong muốn nào của ô nhỏ hơn 5 thì kiểm nghiệm Khi bình phương không thích hợp.
Phương pháp khác đối với kiểm nghiệm tính độc lập là sử dụng hàm tỷ số hợp lý thông qua tỷ số của hai hàm cực đại. Đối với bảng r x c, hàm hợp lý dựa trên phân bố đa thức và thống kê tỷ số hợp lý là
| (3) |
Thống kê này tiệm cận tới phân bố c2. Hai phương pháp thường có cùng đặc tính và đưa ra cùng một kết luận.
Nếu n nhỏ, phân bố thống kê c2 và G2 kém xấp xỉ Khi bình phương hơn. Thông thường, nếu có ít nhất một giá trị mong muốn nhỏ hơn 5 (trong phần mềm thống kê, chuẩn mực hơi khác nhau) thì kiểm nghiệm chính xác Fisher được sử dụng. Trong trường hợp này, dữ liệu quan trắc tuân theo phân bố siêu hình học, là phân bố chính xác của dữ liệu. Tính toán khi đó phức tạp hơn nhiều so với c2 và G2 nên phần mềm thống kê thường được sử dụng. Có một cách khác để xử lý trường hợp này khi giá trị mong muốn quá nhỏ. Có thể ghép hàng hoặc cột với hàng hoặc cột liền kề để tăng giá trị mong muốn trước khi kiểm nghiệm tính độc lập. Tuy nhiên, cần sử dụng giải pháp này thận trọng; việc ghép các cột/hàng có thể làm giảm khả năng giải thích và cũng có thể tạo mới hoặc phá hủy cấu trúc trong bảng. Nếu không có hướng dẫn rõ ràng, nên tránh phương pháp ghép như vậy.
Cần chú ý rằng kiểm nghiệm Khi bình phương về cơ bản là kiểm nghiệm mức ý nghĩa. Nó có thể giúp quyết định liệu mối quan hệ có tồn tại hay không, nhưng không thể xác định được độ mạnh của mối liên hệ. Kiểm nghiệm Khi bình phương không phải là thước đo độ mạnh của mối liên hệ.
Trong tiêu chuẩn này, kiểm nghiệm Khi bình phương được sử dụng để đánh giá ba loại so sánh: kiểm nghiệm sự phù hợp, kiểm nghiệm tính độc lập và kiểm nghiệm tính thuần nhất.
a) Kiểm nghiệm sự phù hợp so sánh các giá trị quan trắc và phân bố lý thuyết để xác định xem dự đoán thực nghiệm có phù hợp với dữ liệu hay không.
b) Kiểm nghiệm tính độc lập xác định xem có mối liên hệ có ý nghĩa giữa hai biến phân loại hay không.
c) Kiểm nghiệm tính thuần nhất so sánh hai tập hợp loại để xác định xem hai nhóm có được phân bố khác nhau giữa các loại hay không.
5.6.2 Kiểm nghiệm xu hướng tuyến tính
Khi cả biến hàng và biến cột là dữ liệu thứ tự, kiểm nghiệm xu hướng tuyến tính có thể được sử dụng để kiểm nghiệm xem có xu hướng khi biến thay đổi giá trị hay không. Tuy nhiên, biến nhị phân cũng có thể được xử lý như dữ liệu thứ tự (ví dụ, không có bệnh tim là điều kiện rủi ro “thấp” so với có bệnh tim là điều kiện rủi ro “cao”), có hai xu hướng. Hai biến thứ tự cho trước X và Y, khi mức của X tăng, đáp ứng Y có xu hướng tăng lên mức cao hơn (xu hướng tuyến tính dương), hoặc đáp ứng Y có xu hướng giảm xuống bậc thấp hơn (xu hướng tuyến tính âm).
Hệ số tương quan là nhạy với xu hướng tuyến tính. Hai hệ số tương quan thường được sử dụng là tương quan Pearson r và Spearman rho. Tương quan Pearson là thước đo mối liên hệ tuyến tính giữa hai biến. Tính toán hệ số tương quan Pearson r dựa trên giá trị số quan trắc. Hệ số Spearman rho là thống kê phi tham số, sử dụng thống kê hạng thay cho giá trị số của các quan trắc.
Ba hệ số tương quan khác đánh giá liên kết xu hướng là hệ số Goodman và hộ số Kruskal g, hệ số Kendall t (tau-b) và hệ số Somers D. Các phương pháp phi tham số này phụ thuộc vào điểm dữ liệu trong các hàng hoặc cột, chứ không phụ thuộc vào giá trị định lượng của mỗi ô.
Giá trị của hệ số tương quan trải từ -1 đến 1. Giá trị càng gần đến 1, xu hướng tuyến tính càng dương; giá trị càng gần đến -1, xu hướng tuyến tính càng âm. Nếu giá trị bằng 0, thì không có mối tương quan nào. Hệ số Kendall t, giống như hệ số Goodman và hệ số Kruskal g đều kiểm nghiệm mức ý nghĩa về sự liên kết giữa các biến thứ tự và nó bao gồm các cặp trùng lặp (các cặp giống nhau) vào phép tính, trong khi g thì bỏ qua. Đối với hệ số Somers D, D R|C và D C|R, đo độ mạnh và chiều của mối quan hệ giữa các cặp biến, với biến hàng và biến cột tương ứng là các biến đáp ứng.
Các hệ số này chỉ đưa ra kết quả về khả năng kết hợp xu hướng, nhưng kiểm nghiệm kết hợp xu hướng thể hiện độ mạnh của mối quan hệ. Đối với mỗi hệ số, tính thống kê kiểm nghiệm z (z = y, t hoặc d) và sai số tiêu chuẩn σz. Thống kê là
| (4) |
với giả thuyết không H0 biến X và Y độc lập. U có phân bố chuẩn chuẩn hóa tiệm cận khi H0 đúng. Bác bỏ giả thuyết không nếu p-giá trị nhỏ hơn giá trị quy định trước, thường lấy là 0,05.
Mô hình loga tuyến tính là một phương pháp hữu ích khác cho phân tích bảng chéo, không được đề cập trong tiêu chuẩn này. Mô hình quy định cách đếm các ô mong muốn dựa trên các mức của biến phân loại và cho phép phân tích liên kết và các dạng tương tác giữa các biến. Nó thường sử dụng cho các bảng nhiều chiều. Phương pháp Mô hình loga tuyến tính cần một số tính toán thường là với sự trợ giúp của máy tính.
5.6.3 Phân tích tương ứng
Phân tích tương ứng (CA) là phương pháp thống kê trực quan để phân tích liên kết giữa các mức của biến hàng và cột trong bảng chéo hai chiều. Kỹ thuật này chuyển các hàng và cột như là các điểm trong không gian hai chiều, sao cho vị trí của điểm hàng và cột phù hợp với sự liên kết của chúng trong bảng.
CA thay đổi bảng dữ liệu thành hai bộ biến mới gọi là “điểm nhân tố” (thu được như tổ hợp tuyến tính hàng và cột, tương ứng). Điểm nhân tố thể hiện sự tương đồng về cấu trúc hàng và cột. Vẽ điểm nhân tố trên một mặt phẳng hiển thị thông tin tối ưu trong bảng gốc. Đồ thị này là biểu diễn đối xứng chuẩn của CA.
CA liên quan mật thiết với kiểm nghiệm Khi bình phương độc lập. Tổng phương sai (thường gọi là “quán tính”) của điểm nhân tố tỷ lệ thuận với thống kê c2 độc lập và điểm nhân tố trong CA phân tách c2 này thành các thành phần vuông góc.
Trong đồ thị CA đối xứng, khoảng cách giữa hai điểm hàng (cột tương ứng) trên mặt phẳng tọa độ là thước đo sự tương đồng về dạng dữ liệu tần số tương đối hàng (cột tương ứng). Nếu hai điểm hàng (cột tương ứng) gần nhau, thì nó cho thấy rằng có các điểm có biên dạng tương tự. Tuy nhiên vị trí của các điểm hàng và cột không thể so sánh trực tiếp được với nhau và cần được giải thích cẩn thận. Trong trường hợp này, sử dụng đồ thị bất đối xứng để thay thế. Trong đồ thị bất đối xứng, khoảng cách từ điểm hàng đến điểm cột phản ánh trực tiếp sự liên kết của chúng.
5.7 Kết luận
Đối với kiểm nghiệm tính độc lập, khi p-giá trị nhỏ hơn mức ý nghĩa quy định, nó thể hiện sự liên kết có ý nghĩa giữa các biến và giả thuyết không là hai biến độc lập cần bị bác bỏ.
Khi tính hệ số tương quan đối với các biến thứ tự, hệ số dương z (0 < z ≤ 1) có nghĩa là các biến có xu hướng dương; hệ số âm z (-1 ≤ z < 0) cho thấy xu hướng âm. Từ kiểm nghiệm xu hướng tuyến tính đánh giá độ mạnh của xu hướng dương hoặc xu hướng âm, p-giá trị nhỏ (nhỏ hơn mức ý nghĩa) cho thấy có bằng chứng về xu hướng dương hoặc xu hướng âm.
Đồ thị tương ứng thể hiện sự liên kết của các mức hàng và cột khác nhau. Nhìn chung, các điểm càng gần, sự giống nhau giữa chúng càng nhiều.
6 Mô tả phụ lục A đến phụ lục D
Bốn ví dụ về phân tích bảng chéo khác nhau được minh họa trong các phụ lục đã được tóm tắt trong Bảng 3 biểu thị các khía cạnh khác biệt.
Bảng 3 - Tóm tắt ví dụ được liệt kê ở phụ lục
Phụ lục | Ví dụ | Chi tiết phân tích bảng chéo |
A | Phân bố một số vấn đề kỹ thuật được tìm thấy sau khi lưu hành sản phẩm | Kiểm nghiệm sự phù hợp, JMP |
B | Cảm nhận của bạn về cuộc sống viên mãn là gì? | Bảng 3 x 5, kiểm nghiệm tính độc lập, kiểm nghiệm tương ứng, phần mềm Minitab |
C | Nghiên cứu sự hài lòng của khách hàng về bia | Bảng 3 x 3, kiểm nghiệm tính độc lập, kiểm nghiệm chính xác Fisher, kiểm nghiệm xu hướng tuyến tính, kiểm nghiệm tương ứng, phần mềm SAS |
D | Tỷ lệ các chi tiết không phù hợp của dây chuyền sản xuất | Bảng 4 x 2, kiểm nghiệm tính độc lập, phần mềm Q-DAS |
Phụ lục A
(tham khảo)
Phân bố một số vấn đề kỹ thuật được tìm thấy sau khi hưu hành sản phẩm2)
A.1 Khái quát
Trong ngành công nghiệp viễn thông, các nền tảng mới như nền tảng thiết bị di động mới hoặc nền tảng trạm thu phát sóng mới (BTS) theo các quá trình kiểm nghiệm trước khi lưu hành rất phức tạp và kéo dài trước khi “lưu hành” để tối ưu hóa thành công và hiệu quả của sản phẩm khi được đưa vào thực tế. Nhiều sản phẩm có khả năng được lưu hành đối với một nền tảng đã có, với từng sản phẩm cũng trải qua một quá trình trước khi lưu hành, đơn giản và ngắn hơn so với quá trình trước khi lưu hành của nền tảng mới, nhưng vẫn khá rộng. Đối với sản phẩm cho trước, nhiều sửa đổi bao gồm những cải tiến nhỏ cho sản phẩm cũng sẽ được đưa ra theo quá trình trước khi lưu hành quy định. Quá trình trước khi lưu hành nhiều cấp phức tạp này được ghi lại đầy đủ và các sản phẩm tương ứng là một nền tảng mới, sản phẩm mới trong nền tảng hoặc sửa đổi phần cứng hoặc phần mềm trong một sản phẩm trải qua kiểm nghiệm đáng kể (kiểm tra, xác nhận, kiểm nghiệm hồi quy, v.v...) trước khi chúng được lưu hành.
Hiệu lực và hiệu quả của quá trình trước khi lưu hành được đánh giá sau khi lưu hành dựa trên một số vấn đề do khách hàng báo đến trung tâm hỗ trợ kỹ thuật. Khi sản phẩm được lưu hành, nó được theo dõi chặt chẽ trong khoảng thời gian một năm để nắm bắt và sửa chữa nhanh nhất có thể mọi vấn đề có thể bị bỏ qua trong quá trình trước khi lưu hành. Do đó, cần phân bố nhân lực thích hợp cho mục đích này. “Bài học kinh nghiệm” được xây dựng là tại sao các vấn đề bị bỏ sót, cũng như tại sao các vấn đề xảy ra lần đầu và các hành động để ngăn ngừa chúng trong tương lai.
Tại bất kỳ thời điểm nào, có khoảng 200 sản phẩm, tất cả đều trong một khoảng thời gian từ ngày lưu hành được trung tâm hỗ trợ kỹ thuật theo dõi đồng thời. Mọi vấn đề kỹ thuật tìm thấy trên những sản phẩm này được phân loại thành mức A, B hoặc C, với mức A là ưu tiên cao nhất và có khả năng gây ra “chấm dứt gửi hàng”, mức B là ưu tiên tiếp theo và mức C là ưu tiên thấp nhất vì loại đó bao gồm các vấn đề không ảnh hưởng trực tiếp đến người sử dụng, số vấn đề kỹ thuật mức A và B được theo dõi trên cơ sở hàng giờ và phân bố của nó được mô hình hóa để cung cấp thông tin về mức độ nhân lực cần thiết của trung tâm để đảm bảo sự thỏa mãn của khách hàng.
A.2 Thuộc tính quan tâm
Dữ liệu quan tâm bao gồm số vấn đề kỹ thuật mức A và B được trung tâm hỗ trợ khách hàng về mặt kỹ thuật nhận và ghi nhận hàng giờ. Chỉ các vấn đề kỹ thuật gắn với các sản phẩm đã lưu hành dưới một năm mới được quan tâm trong nghiên cứu này - rất hiếm tìm thấy các vấn đề kỹ thuật quan trọng có thể thấy được đối với người sử dụng sau khi lưu hành năm đầu tiên. Dữ liệu này cần thiết để ước lượng nhân lực của trung tâm kỹ thuật nhằm đảm bảo giải quyết nhanh chóng và đầy đủ các vấn đề của khách hàng.
A.3 Giả thuyết
Giả thuyết không là số vấn đề kỹ thuật ghi nhận hàng giờ tuân theo phân bố Poisson với trung bình và độ lệch chuẩn được ước lượng từ dữ liệu. Phân bố Poisson là phân bổ được sử dụng rất phổ biến để mô hình hóa số khuyết tật xuất hiện trong một khoảng thời gian quy định.
H0: Số vấn đề kỹ thuật A/B nhận được hàng giờ của trung tâm kỹ thuật tuân theo phân bố Poisson.
Ha: Số vấn đề kỹ thuật A/B nhận được hàng giờ của trung tâm kỹ thuật không tuân theo phân bố Poisson.
A.4 Phương án lấy mẫu
Trung tâm hỗ trợ khách hàng về mặt kỹ thuật cung cấp nhật ký về tất cả các vấn đề kỹ thuật được báo cáo trong hoạt động hàng tuần 10 h x 6 ngày. Đối với nghiên cứu này, “mẫu” bao gồm tất cả các vấn đề kỹ thuật mức A/B nhận được trong hai tuần cuối (120 h) và giả định là hai tuần này là mẫu “đại diện” cho các tuần đã qua và các tuần sắp tới.
A.5 Dữ liệu thô
Dữ liệu được trình bày trong Bảng A.1.
Bảng A.1 - Số vấn đề kỹ thuật A/B sau khi lưu hành sản phẩm năm đầu tiên được ghi nhận hàng giờ
Số vấn đề kỹ thuật A/B sau khi lưu hành năm đầu tiên ghi nhận hàng giờ trong tuần kiểm tra | Tần số |
0 | 96 |
1 | 11 |
2 | 6 |
3 | 1 |
4 | 3 |
5 | 0 |
6 | 2 |
7 | 1 |
8 | 0 |
9 | 0 |
10 | 0 |
A.6 Phân tích
Phân tích dữ liệu trong Bảng A.1 được thực hiện với phần mềm SAS JMP Pro phiên bản 11. Thống kê tóm tắt được đưa ra trong Bảng A.2.
Bảng A.2 - Thống kê tóm tắt
Trung bình | 0.475 |
Độ lệch chuẩn | 1,249 958 |
Sai số chuẩn của trung bình | 0,114 105 |
N | 120 |
Sẽ hữu ích khi nhìn vào thống kê tóm tắt, đặc biệt là trung bình (0,475) và độ lệch chuẩn (1,25). Phân bố Poisson có đặc trưng là trung bình và phương sai của nó bằng nhau, ở đây, phương sai mẫu là 1,562 4, có phần lớn hơn trung bình và điều này đặt ra câu hỏi liệu phân bố Poisson có phù hợp với dữ liệu hay không.
Hình A.1 thể hiện phân bố Poisson phù hợp với dữ liệu, với thiết lập trung bình bằng với trung bình mẫu. Đường kẻ đậm là phân bố phù hợp.
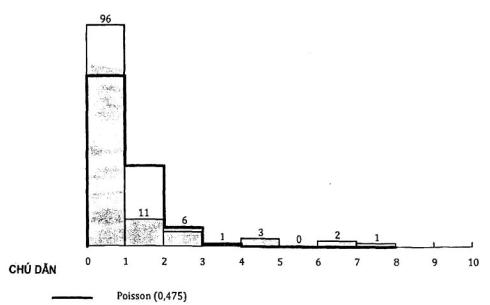
Hình A.1 - Biểu đồ số vấn đề kỹ thuật A/B xảy ra hàng giờ và phân bố Poisson phù hợp
Bảng A.3 - Số vấn đề kỹ thuật A/B xảy ra hàng giờ và tần số mong muốn
Số vấn đề kỹ thuật A/B sau khi lưu hành năm đầu tiên hàng giờ trong tuần kiểm tra | Tần số (Số giờ) | Tần số mong muốn với phân bố Poisson |
0 | 96 | 74,63 |
1 | 11 | 35,45 |
2 | 6 | 8,42 |
3 | 1 | 1,33 |
4 | 3 | 0,16 |
5 | 0 | 0,02 |
6 | 2 | 0,00 |
7 | 1 | 0,00 |
8 | 0 | 0,00 |
9 | 0 | 0,00 |
10 | 0 | 0,00 |
Có một vài ô trong Bảng A.3 có tần số mong muốn nhỏ hơn 5. Để đảm bảo hiệu lực của kiểm nghiệm Khi bình phương Pearson về sự phù hợp, nhóm lại các ô có số ô nhỏ hơn như được trình bày trong Bảng A.3.
Bảng A.4 - Số hợp nhất các vấn đề kỹ thuật A/B hàng giờ về tính toán sự phù hợp với phân bố Poisson
Số hợp nhất các vấn đề kỹ thuật A/B sau khi lưu hành năm đầu tiên hàng giờ | Tần số | Xác suất mong muốn với các ô hợp nhất | Tần số mong muốn với phân bố Poisson | Thành phần Khi bình phương | Thống kê Khi bình phương | p-giá trị |
0 | 96 | 0,622 | 74,63 | 6,12 | - | - |
1 | 11 | 0,295 | 35,45 | 16,86 | - | - |
2+ | 13 | 0,083 | 9,93 | 20,70 | - | - |
- | - | - | - | - | 43,69 | <0,001 |
A.7 Kết luận
Giả thuyết không bị bác bỏ và không sử dụng được phân bố Poisson để đưa ra dự đoán về số nhân lực cần thiết hoặc cải tiến trong quá trình lưu hành.
Có các phân bố khác có thể phù hợp với các dữ liệu này. Đặc biệt, trong trường hợp loại dữ liệu số đếm và quả phân tán (phương sai lớn hơn trung bình là tình huống trong phụ lục này), phân bố Poisson Gamma còn được gọi là “phân bố nhị thức âm” thường phù hợp hơn phân bố Poisson vì nó phát sinh từ việc trộn phân bố Poisson với giá trị trung bình tuân theo phân bố Gamma. Nếu số vấn đề kỹ thuật A/B từ mỗi sản phẩm tuân theo phân bố Poisson nhưng trung bình của phân bố Poisson đối với các sản phẩm khác nhau tuân theo phân bố Gamma, thì phân bố sinh ra của các vấn đề kỹ thuật A/B hiện đang được quan trắc sẽ tuân theo phân bố Poisson Gamma.
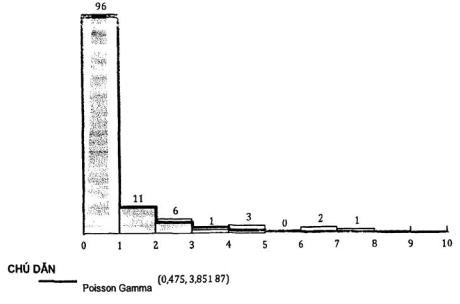
Hình A.2 - Biểu đồ số vấn đề kỹ thuật A/B ghi nhận hàng giờ và phân bố Poisson Gamma phù hợp
Có một vài ô trong Bảng A.3 có tần số mong muốn nhỏ hơn 5. Để đảm bảo hiệu lực của kiểm nghiệm Khi bình phương Pearson về sự phù hợp đối với phân bố Poisson Gamma, nhóm các ô có số ô nhỏ như được trình bày trong Bảng A.5.
Bảng A.5 - Số hợp nhất các vấn đề kỹ thuật A/B hàng giờ và tính toán sự phù hợp với phân bố Poisson Gamma
Số hợp nhất các vấn đề kỹ thuật A/B sau khi lưu hành năm đầu tiên hàng giờ | Tần số | Xác suất mong muốn với các ô hợp nhất | Tần số mong muốn với Poisson Gamma | Thành phần Khi bình phương | Thống kê Khi bình phương | p-giá trị |
0 | 96 | 0,799 | 95,86 | 0,000 | - | - |
1 | 11 | 0,099 | 11,82 | 0,057 | - | - |
2 | 6 | 0,043 | 5,10 | 0,157 | - | - |
3+ | 7 | 0,060 | 7,21 | 0,006 | - | - |
| - | - | - | - | 0,221 | 0,638 |
Lần này, giả thuyết không, H0, dữ liệu lấy từ phân bố Poisson Gamma, không bị bác bỏ và do đó nó có thể được sử dụng cho mục đích tuyển dụng nhân viên. Như lưu ý trước đó, phân bố Poisson Gamma cũng được gọi là “phân bố nhị thức âm”.
Bảng A.6 - Ước lượng tham số
Loại | Tham số | Ước lượng | Cận dưới 95 % | Cận trên 95 % |
Vị trí | l | 0,475 | 0,287 350 2 | 0,824 818 2 |
Độ phân tán quá mức | σ | 3,851 874 4 | 2,321 399 5 | 8,015 828 6 |
2 log (hợp lý) = 197,831 173 887 326 | ||||
Từ Bảng A.6, dữ liệu tuân theo phân bố Poisson Gamma với l = 0,475 và σ = 3,85.
Cần phải xác nhận một lần nữa trước khi chọn phân bố Poisson Gamma cho số vấn đề kỹ thuật A/B hàng giờ. Nó liên quan đến giả định về “tính đại diện” mẫu dữ liệu trong hai tuần.
Dữ liệu được thu thập thêm một tuần nữa (60 h) để đảm bảo phân bố các vấn đề kỹ thuật được ghi hàng giờ là ổn định (tương tự như giai đoạn phân tích hai tuần). Dữ liệu được cho trong Bảng A.7.
Bảng A.7 - Tần số các vấn đề kỹ thuật A/B hàng giờ cho một tuần bổ sung 60 h
Số vấn đề kỹ thuật A/B sau khi lưu hành năm đầu tiên hàng giờ trong tuần kiểm tra | Tần số (Số giờ) |
0 | 48 |
1 | 6 |
2 | 3 |
3 | 0 |
4 | 2 |
5 | 0 |
6 | 1 |
7 | 0 |
8 | 0 |
9 | 0 |
10 | 0 |
Bảng A.8 - Thống kê tóm tắt
Trung bình | 0,433 3333 |
Độ lệch chuẩn | 1,125 4629 |
Sai số chuẩn của trung bình | 0,145 2966 |
N | 60 |
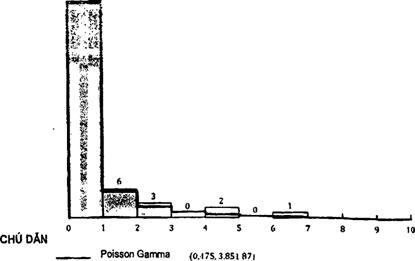
Hình A.3 - Biểu đồ số vấn đề kỹ thuật A/B ghi nhận hàng giờ đối với một tuần bổ sung 60 h và phân bố Poisson Gamma phù hợp
Hình A.3 cho thấy dữ liệu của tuần bổ sung phù hợp rất tốt với phân bố Poisson Gamma (0,475,3 851 87). Không đủ để đưa ra kết luận rằng hai bộ dữ liệu theo cùng phân bố. Kiểm nghiệm có thể được thực hiện bằng cách sử dụng kiểm nghiệm tỉ số hợp lý như sau:
Bảng A.9 - Ước lượng tham số (từ dữ liệu bổ sung)
Loại | Tham số | Ước lượng | Cận dưới 95 % | Cận trên 95 % |
Vị trí | l | 0,433 333 3 | 0,214 826 2 | 0,960 899 7 |
Độ phân tán quá mức | σ | 3,315 128 8 | 1,751 931 1 | 9,907 578 1 |
-2 log (hợp lý) = 95,969 897 007 548 6 | ||||
Bảng A.10 - Ước lượng tham số (từ dữ liệu kết hợp)
Loại | Tham số | Ước lượng | Cận dưới 95 % | Cận trên 95 % |
Vị trí | l | 0,461 111 1 | 0,306 933 2 | 0,713 208 9 |
Độ phân tán quá mức | σ | 3,671 538 9 | 2,410920 8 | 6,488 796 |
-2 log (hợp lý) = 293,883 609 376 736 | ||||
Thống kê tỉ số hợp lý được tính như sau:
G = 293,883 609 376 736 - (197,831 173 887 326 + 95,969 897 007 548 6) = 0,082 538 48
p-giá trị được đánh giá trong phân bố Khi bình phương với 2 bậc tự do. Các giá trị lớn là tới hạn đối với giả thuyết không, p-giá trị là 0,959 570 7 = 0,96
Kiểm nghiệm tỉ số hợp lý này dùng để kiểm nghiệm giả thuyết không mà các tham số của phân bố Poisson Gamma của hai mẫu là như nhau. Phân bố Khi bình phương có 2 bậc tự do vì số tham số chưa biết giảm đi 2, từ 4 xuống còn 2 tham số chưa biết.
Kết luận, phân bố Poisson Gamma ước lượng với các tham số cố định 0,475 và 3,851 9 phù hợp với dữ liệu thu thập trong tuần kiểm tra và có thể sử dụng phân bố cho mục đích xác định nhân lực, cũng như đánh giá cải tiến được thực hiện cho quá trình trước lưu hành sẽ được thực hiện trong tương lai.
Phụ lục B
(tham khảo)
Cảm nhận của con người về cuộc sống viên mãn3)
B.1 Khái quát
Tổ chức “Trung tâm nghiên cứu Manashakti (MRC)” nằm ở Lonawala (cách Mumbai khoảng 100 km, địa chỉ là 76, đường Mumbai-Pune, Varsoli Lonavla 410401, Maharashtra, Ấn Độ), miền tây của Ấn Độ, các hoạt động hướng tới phúc lợi của xã hội và có các chương trình dành cho các bà mẹ mang thai/ thai nhi, trẻ em và người lớn ở mọi lứa tuổi. Trung tâm hoạt động mà không có nguồn tài trợ và sự hỗ trợ của chính phủ. Các tình nguyện viên của tổ chức dành thời gian của họ và các gia đình tham dự các hội thảo phải trả phí danh nghĩa. Có khoảng 80 gia đình đã dành cả cuộc đời của họ cho các hoạt động của trung tâm. MRC gần đây đã tiến hành một cuộc khảo sát các nhóm tuổi khác nhau để điều tra cảm nhận của con người về cuộc sống viên mãn.
B.2 Thuộc tính quan tâm
Trong khảo sát này, một trong những câu hỏi đề hỏi những người tham gia trong nhóm tuổi 25 đến 40, 41 đến 60 và trên 60 là
Cảm nhận của bạn về cuộc sống viên mãn là gì?
A) Nhiều tiền
B) Mức sống cao
C) Gia đình yên ấm
D) Uy tín
E) Hoàn thành trách nhiệm/tiến bộ tinh thần
Số lượng của mỗi lựa chọn giữa các nhóm tuổi khác nhau được ghi lại.
B.3 Dữ liệu thô
Bảng B.1 liệt kê dữ liệu thô.
Bảng B.1 - Phân loại chéo cảm nhận của con người về cuộc sống viên mãn
Nhóm tuổi | Mã | ||||
A | B | C | D | E | |
25 đến 40 | 25 | 69 | 538 | 11 | 12 |
41 đến 60 | 17 | 49 | 467 | 7 | 85 |
Từ 61 trở lên | 6 | 29 | 271 | 5 | 57 |
B.4 Phân tích bảng chéo
Phân tích bảng chéo được thực hiện bằng Minitab164).
B.4.1 Kiểm nghiệm tính độc lập
Kiểm nghiệm Khi bình phương được sử dụng để kiểm nghiệm xem có mối liên hệ nào giữa độ tuổi và cảm nhận của họ về cuộc sống viên mãn hay không.
Giả thuyết không H0: độ tuổi và cảm nhận của họ về cuộc sống viên mãn là độc lập.
Đối giả thuyết Ha: độ tuổi cảm nhận của họ về cuộc sống viên mãn là không độc lập.
Thống kê trong Bảng B.2 thể hiện số đếm, số đếm mong muốn thành phần Khi bình phương đối với mỗi ô.
Bảng B.2 - Thống kê theo bảng
| A | B | Cc | D | E | Tất cả |
25 đến 40 | 25 | 69 | 538 | 11 | 12 | 655 |
19,08 | 58,43 | 507,15 | 9,14 | 61,21 | 655,00 | |
1,8385 | 1,9139 | 1,8769 | 0,3779 | 39,560 2 | - | |
41 đến 60 | 17 | 49 | 467 | 7 | 85 | 625 |
18,20 | 55,75 | 483,92 | 8,72 | 58,40 | 625,00 | |
0,0796 | 0,8171 | 0,5916 | 0,3402 | 12,111 1 | - | |
Từ 61 trở lên | 6 | 29 | 271 | 5 | 57 | 368 |
10,72 | 32,83 | 284,93 | 5,14 | 34,39 | 368,00 | |
2,077 1 | 0,445 8 | 0,681 2 | 0,003 6 | 14,868 0 | - | |
Tất cả | 48 | 147 | 1 276 | 23 | 154 | 1648 |
48,00 | 147,00 | 1 276,00 | 23.00 | 154,00 | 1648,00 | |
- | - | - | - | - | - | |
Nội dung ô: | Số đếm Số đếm mong muốn Đóng góp cho Khi bình phương | |||||
Khi bình phương Pearson = 77,583, DF = 8, p-giá trị = 0,000 Tỷ số hợp lý Khi bình phương = 93,506, DF = 8, p-giá trị = 0,000 | ||||||
Giá trị Khi bình phương là 77,583 và p-giá trị là 0,000 nhỏ hơn mức ý nghĩa 5 % cho thấy rằng giả thuyết không H0 cần được bác bỏ, nghĩa là độ tuổi và cảm nhận của họ về cuộc sống viên mãn là không độc lập.
B.4.2 Phân tích tương ứng
Bảng B.3 đưa ra các kết quả phân tách quán tính và Khi bình phương.
Bảng B.3 - Phân tích Khi bình phương
Chiều | Quán tính | Phần trăm | Phần trăm tích lũy |
1 | 0,046 6 | 0,989 9 | 0,989 9 |
2 | 0,000 5 | 0,010 1 | 1,000 0 |
Tổng | 0,047 1 | - | - |
Tổng quán tính là 0,047 08 và 98,99 % của tổng quán tính có thể được giải thích bằng chiều 1.
Bảng B.4 - Đóng góp hàng
ID | Tên | Chiều 1 | Chiều 2 |
|
| Tọa độ | Tọa độ |
1 | Từ 25 đến 40 tuổi | -0,264 | 0,003 |
2 | Từ 41 đến 60 tuổi | 0,147 | -0,024 |
3 | Từ 61 tuổi trở lên | 0,219 | 0,034 |
Bảng B.5 - Đóng góp cột
ID | Tên | Chiều 1 | Chiều 2 |
Tọa độ | Tọa độ | ||
1 | A | -0,268 | -0,108 |
2 | B | -0,146 | 0,020 |
3 | c | -0,050 | 0,001 |
4 | D | -0,156 | 0,084 |
5 | E | 0,657 | -0,006 |
Bảng B.4 và B.5 thể hiện tọa độ của các mức hàng và cột. Vẽ các điểm này trên mặt phẳng hai chiều, thu được Hình B.1.
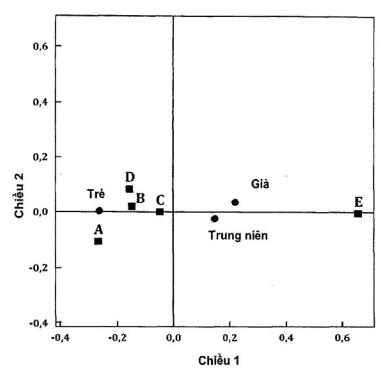
CHÚ DẪN:
trẻ | từ 25 đến 40 tuổi |
trung niên | từ 41 đến 60 tuổi |
già | từ 61 tuổi trở lên |
A | nhiều tiền |
B | mức sống cao |
C | gia đình yên ấm |
D | uy tín |
E | hoàn thành trách nhiệm/tiến bộ tinh thần |
Hình B.1 - Đồ thị phân tích tương ứng đối xứng
Đồ thị phân tích tương ứng trên Hình B.1 thể hiện người già và trung niên có cảm nhận giống nhau về cuộc sống viên mãn, khác với người trẻ. Câu trả lời E được tách biệt với tất cả các câu trả lời khác.
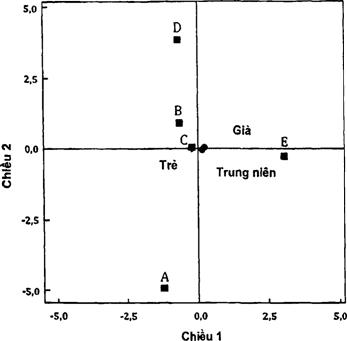
CHÚ DẪN:
trẻ | từ 25 đến 40 tuổi |
trung niên | từ 41 đến 60 tuổi |
già | từ 61 tuổi trở lên |
A | nhiều tiền |
B | mức sống cao |
C | gia đình yên ấm |
D | uy tín |
E | hoàn thành trách nhiệm/tiến bộ tinh thần |
Hình B.2 - Đồ thị phân tích tương ứng không đối xứng
Hình B.2 cho thấy người trẻ có cảm nhận về cuộc sống viên mãn hơi khác so với tuổi trung niên và người già. Tất cả họ đều chọn sự yên ấm trong gia đình, mức sống cao và uy tín tương đối nhiều hơn. Trong khi người trung niên và người già coi việc hoàn thành trách nhiệm/tiến bộ tinh thần nhiều hơn so với người trẻ.
B.5 Kết luận
Các kết quả Minitab ở trên chỉ ra rằng con người ở nhóm tuổi khác nhau có cảm nhận khác nhau về cuộc sống viên mãn. Người trẻ và già hơn có những xem xét khác nhau. Người trẻ thường coi gia đình, mức sống cao và uy tín là quan trọng trong cuộc sống của họ, nhưng đối với người già trên 40 thì việc hoàn thành trách nhiệm/tiến bộ tinh thần được coi là quan trọng hơn.
Phụ lục C
(tham khảo)
Nghiên cứu sự hài lòng của khách hàng về nhãn hiệu bia5)
C.1 Khái quát
Mức độ hài lòng của khách hàng với nhãn hiệu bia cụ thể được nghiên cứu ở Trung Quốc. Nghiên cứu này dựa trên khảo sát đối với 243 người có độ tuổi trên 18. Tất cả những người được phỏng vấn trả lời một số câu hỏi, bao gồm độ tuổi, mức độ hài lòng với loại bia này, v.v...Việc khảo sát lấy mẫu này sẽ giúp công ty thu thập thông tin về sở thích của khách hàng liên quan đến độ tuổi khác nhau. Mối quan hệ về độ tuổi của khách hàng và mức độ hài lòng của họ sẽ giúp đưa ra chiến lược mục tiêu xa hơn để dành nhiều thị phần hơn.
C.2 Thuộc tính quan tâm
Để điều tra sự hài lòng của khách hàng Trung Quốc về bia, bảng câu hỏi bao gồm tuổi của người được phỏng vấn và mức độ hài lòng. Biến tuổi được phân thành ba loại: trẻ (từ 18 đến 39 tuổi), trung niên (từ 40 đến 59 tuổi) và già (từ 60 tuổi trở lên). Các mức độ hài lòng được phân thành ba mức: thấp, trung bình và cao. Biến đáp ứng đếm có bao nhiêu người được phỏng vấn ở mỗi nhóm tuổi đều thỏa mãn với bia ở mọi mức độ. Có chín kết hợp có thể của việc đếm. Mục tiêu của việc nghiên cứu là để tìm kiếm xem có tồn tại mối liên hệ giữa tuổi của khách hàng và mức độ hài lòng của họ với bia và các mối quan hệ tương ứng hay không.
C.3 Thiết kế phương án lấy mẫu cho nghiên cứu
Điều tra sự hài lòng của khách hàng được thực hiện bằng khảo sát qua điện thoại. Tổng số người được phỏng vấn không cố định. Tất cả mọi người được lựa chọn ngẫu nhiên để trả lời bảng câu hỏi trong khoảng thời gian nhất định.
C.4 Dữ liệu thô
Bảng C.1 liệt kê dữ liệu thu thập được.
Bảng C.1 - Phân loại chéo sự hài lòng của khách hàng về bia
Tuổi | Đánh giá sự hài lòng | ||
Thấp | Trung bình | Cao | |
Trẻ | 3 | 45 | 86 |
Trung niên | 1 | 18 | 61 |
Già | 3 | 3 | 23 |
C.5 Phân tích bảng chéo
Phân tích bảng chéo trong SAS6) được sử dụng để đánh giá tính độc lập và xu hướng tuyến tính của các biến phân loại, cũng như phân tích tương ứng đưa ra sụ thể hiện trực quan về các mối quan hệ giữa loại hàng và cột.
C.5.1 Kiểm nghiệm tính độc lập
Kiểm nghiệm Khi bình phương được chấp nhận để kiểm nghiệm tính độc lập của các biến hàng và cột.
Giả thuyết không H0: độ tuổi của khách hàng và mức độ hài lòng của họ là độc lập.
Đối giả thuyết Ha: độ tuổi của khách hàng và mức độ hài lòng của họ là không độc lập.
Thống kê trong Bảng C.2 thể hiện tần số, tần số mong muốn và Khi bình phương đối với mỗi ô. Người già đánh giá thấp và trung bình đối với bia có hai đóng góp Khi bình phương ô lớn nhất, ngụ ý mức độ hài lòng của người già có thể khác với những người trẻ và trung niên.
Bảng C.2 - Thống kê theo bảng
Tuổi | Đánh giá | Tổng | ||
Tần số Ô mong muốn Khi bình phương | Thấp | Trung bình | Cao | |
Trẻ | 3 3,860 1 0,191 6 | 45 36,395 2,034 5 | 86 93,745 0,639 9 | 134 |
Trung niên | 1 2,304 5 0,738 5 | 18 21,728 0,639 8 | 61 55,967 0,452 6 | 80 |
Già | 3 0,8354 5,608 8 | 3 7,876 5 3,019 2 | 23 20,288 0,362 5 | 29 |
Tổng | 7 | 66 | 170 | 243 |
Các kết quả của kiểm nghiệm tính độc lập được trình bày trong Bảng C.3. Giá trị Khi bình phương giúp đánh giá xem liệu hai biến (tuổi của khách hàng và mức độ hài lòng của họ đối với bia) có độc lập với nhau hay không, p-giá trị thể hiện xác suất để cho thống kê kiểm nghiệm tính được có thể xảy ra, giả định rằng giả thuyết không là đúng. Nếu p-giá trị nhỏ hơn mức ý nghĩa quy định trước (alpha), thường là 0,05 thì giả thuyết không cần được bác bỏ. Nếu bác bỏ giả thuyết không ở mức 5 %, điều này có nghĩa rằng chỉ có 5 % cơ hội sẽ là quá trình giả định tạo ra phát hiện cực trị này nếu giả thuyết không là đúng.
Bảng C.3 - Kiểm nghiệm Khi bình phương
Thống kê | DF | Giá trị | Xác suất |
Khi bình phương | 4 | 13,6873 | 0,0084 |
Tỷ số hợp lý Khi bình phương | 4 | 12,4658 | 0,0142 |
Cảnh báo: 33 % các ô có số đếm mong muốn nhỏ hơn 5. Khi bình phương có thể không phải là kiểm nghiệm phù hợp. | |||
Trong Bảng C.3, giá trị Khi bình phương là 13,687 3 và p-giá trị là 0,008 4, tỷ số hợp lý Khi bình phương là 12,465 8 và p-giá trị là 0,014 2. Cả hai p-giá trị đều nhỏ hơn 0,05 thể hiện giả thuyết không bị bác bỏ. Nhưng chú ý câu cảnh báo: 33 % các ô có số đếm mong muốn nhỏ hơn 5. Khi bình phương có thể không phải là kiểm nghiệm phù hợp. Do đó kiểm nghiệm chính xác Fisher cần được sử dụng trong trường hợp này (xem Bảng C.4).
Bảng C.4 - Kiểm nghiệm chính xác Fisher
Xác suất bảng (P) | 8.282E-06 |
Pr ≤ P | 0,0106 |
Trong Bảng C.4, p-giá trị là 0,010 6 nhỏ hơn 0,05. Điều này cho thấy cần bác bỏ giả thuyết không, nghĩa là bằng chứng cho thấy tuổi của khách hàng và mức độ hài lòng của họ với bia là không độc lập.
Trong Bảng C.2, các giá trị Khi bình phương ô của người già cao hơn nhiều so với các giá trị Khi bình phương ô của khách hàng ở các độ tuổi khác, điều này cho thấy sở thích của người già có thể khác với người trung niên và người trẻ. Để xác nhận kết quả này, kiểm nghiệm được lặp lại mà không có người già.
Bảng C.5- Thống kê theo bảng (với người được phỏng vấn là trẻ và trung niên)
Tuổi | Đánh giá |
| ||
Tần số Mong muốn Khi bình phương ô | Thấp | Trung bình | cao | Tổng |
Trẻ | 3 | 45 | 86 | 134 |
Trung niên | 1 | 18 | 61 | 80 |
Tổng | 4 | 63 | 147 | 214 |
Bảng C.6 - Kiểm nghiệm Khi bình phương (với người được phỏng vấn là trẻ và trung niên)
Thống kê | DF | Giá trị | Xác suất |
Khi bình phương | 2 | 3,414 4 | 0,181 4 |
Tỷ số hợp lý Khi bình phương | 2 | 3,498 9 | 0,173 9 |
Cảnh báo: 33 % các ô có số đếm mong muốn nhỏ hơn 5. Khi bình phương có thể không phải là kiểm nghiệm phù hợp. | |||
Bảng C.5 và C.6 đưa ra các kết quả thống kê và kiểm nghiệm Khi bình phương, nhưng vẫn với cảnh báo là 33 % ô có số đếm mong muốn nhỏ hơn 5, vì vậy kiểm nghiệm Khi bình phương có thể không có giá trị. Sử dụng thêm kiểm nghiệm chính xác Fisher.
Bảng C.7 - Kiểm nghiệm chính xác Fisher (với người được phỏng vấn là trẻ và trung niên)
Xác suất bảng (P) | 0,009 7 |
Pr ≤ P | 0,158 0 |
Các kết quả kiểm nghiệm chính xác Fisher cho thấy p-giá trị là 0,158 0 lớn hơn 0,05 ngụ ý rằng có bằng chứng về tính độc lập giữa những người có độ tuổi dưới 60 và sở thích của họ về bia.
Kiểm nghiệm tính độc lập với tất cả các khách hàng và kiểm nghiệm mà không có khách hàng già cho thấy mức độ hài lòng của người già với bia là khác nhau đáng kể so với khách hàng ở các độ tuổi khác.
C.5.2 Kiểm nghiệm xu hướng tuyến tính
Vì biến hàng và cột đều là dữ liệu thứ tự, nên có thể sử dụng kiểm nghiệm xu hướng tuyến tính để phân tích thêm. Bảng C.8 cho thấy một số giá trị hệ số tương quan đối với biến thứ tự, sai số chuẩn tiệm cận (ASE) đối với mỗi thống kê và 95 % giới hạn tin cậy.
Hệ số tương quan Spearman 0,126 4 cho thấy mối liên quan yếu giữa độ tuổi của khách hàng và mức độ hài lòng của họ. Thống kê Gamma là 0.245 0. Kendall's tau-b là 0,120 9 và Somers' D C|R là 0,105 5 - tất cả cho thấy có một xu hướng tích cực yếu. Trong Bảng C.9 và C.10, p-giá trị trong kiểm nghiệm đối với Kendall's tau-b và Somers’ D C|R tất cả đều nhỏ hơn 0,05, cho thấy sự liên quan tích cực yểu. nghĩa là sự hài lòng với bia có sự gia tăng ít khi độ tuổi tăng lên.
Bảng C.8 - Thống kê đối với phép đo kết hợp
Thống kê | Giá trị | ASE | Giới hạn tin cậy 95 % | |
Gamma | 0,245 0 | 0,125 6 | -0,001 2 | 0,491 3 |
Kendall’s tau-b | 0,120 9 | 0,060 9 | 0,001 6 | 0,240 3 |
Stuart’s tau-c | 0,090 7 | 0,045 7 | 0,001 1 | 0,180 3 |
Somers’ D C|R | 0,105 5 | 0,053 2 | 0,001 2 | 0,209 7 |
Somers' D R|C | 0,138 7 | 0,070 1 | 0,001 3 | 0,276 1 |
Bảng C.9 - Kiểm nghiệm đối với Kendall’s tau-b (kiểm nghiệm H0: tau-b = 0)
ASE theo H0 | 0,060 9 |
Z | 1,9841 |
Một phía Pr > Z | 0,023 6 |
Hai phía Pr > |Z| | 0,047 2 |
Bảng C.10 - Kiểm nghiệm đối với Somers’ D C|D (kiểm nghiệm H0: Somers’ D C|R = 0)
ASE theo H0 | 0,053 2 |
Z | 1,984 1 |
Một phía Pr > Z | 0,023 6 |
Hai phía Pr > |Z| | 0,047 2 |
C.5.3 Phân tích tương ứng
Phân tích tương ứng thể hiện biểu diễn nhiều chiều về sự liên kết giữa các loại hàng và cột. Bảng C.11 cho thấy biên dạng hàng, mỗi giá trị ô thu được bằng tần số của bảng chéo chia cho tổng hàng. Giá trị suy biến cho biết sự liên kết các mức hàng và cột trong mặt phẳng hai chiều.
Bảng C.11 - Biên dạng hàng
| Cao | Trung bình | Thấp |
Trẻ | 0,641 8 | 0,335 8 | 0,022 4 |
Trung niên | 0,762 5 | 0,225 0 | 0,012 5 |
Già | 0,821 4 | 0,107 1 | 0,071 4 |
Khi bình phương trong Bảng C.12 là thống kê tương tự từ kiểm nghiệm Khi bình phương; giá trị là 10,090 8. Quán tính đo cường độ kết hợp hàng và cột. Tổng quán tính là 0,041 7, như vậy 81,32 % trong số đó có thể được giải thích bằng chiều 1, ngụ ý hầu hết các mối quan hệ có thể được giải thích bảng chiều 1.
Bảng C.12 - Phân tích quán tính và Khi bình phương
Giá trị suy biến | Quán tính | Khi bình phương | Phần trăm | Phần trăm tích lũy |
0,184 15 | 0,033 91 | 8,206 2 | 81,32 | 81,32 |
0,088 25 | 0,007 79 | 1,884 6 | 18,68 | 100,00 |
Tổng | 0,041 70 | 10,090 8 | 100,00 | - |
Bậc tự do = 4 | ||||
Bảng C.13 cho thấy chiều đầu tiên phân biệt chủ yếu giữa nhóm người trẻ và những nhóm người khác, nghĩa là người trẻ có đánh giá về bia khác với những người khác. Từ Bảng C.14, loại trung bình ở phía bên trái của gốc cách xa hai loại còn lại.
Bảng C.13 - Tọa độ hàng
| Chiều 1 | Chiều 2 |
Trẻ | -0,133 8 | 0,046 5 |
Trung niên | 0,070 3 | -0,121 0 |
Già | 0,439 6 | 0,123 0 |
Bảng C.14 - Tọa độ cột
| Chiều 1 | Chiều 2 |
Thấp | 0,496 0 | 0,499 8 |
Trung bình | -0,282 9 | 0,048 9 |
Cao | 0,092 3 | -0,036 6 |
Bảng C.13 và C.14 với tọa độ hàng và cột dẫn đến đồ thị phân tán. Đồ thị phân tích tương ứng trên hình C.1 cho biết khách hàng trung niên có mức độ hài lòng cao, người trẻ có mức độ hài lòng trung bình và người già có mức độ hài lòng tương đối thấp.
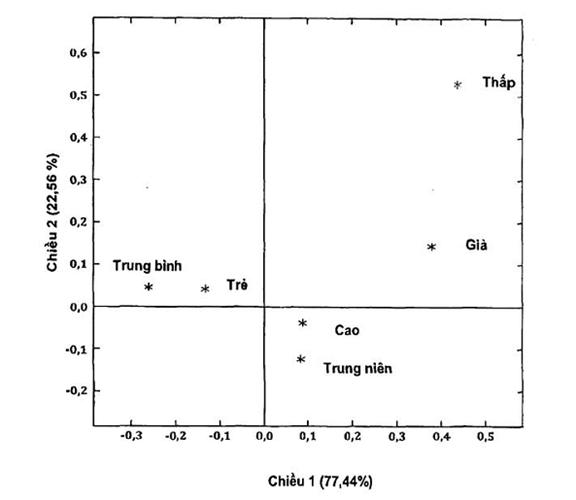
Hình C.1 - Đồ thị phân tích tương ứng bảng
C.6 Kết luận
Kết quả kiểm nghiệm Khi bình phương cho thấy mức độ hài lòng của khách hàng có mối liên quan với độ tuổi của khách hàng. Có sự liên quan tích cực yếu giữa hai loại, người già có khuynh hướng đánh giá cao hơn về bia.
Dựa trên đồ thị phân tích tương ứng, người trẻ thể hiện sự hài lòng trung bình với bia, người trung niên cho thấy sự hài lòng cao và người già có sự hài lòng tương đối thấp.
Có sở thích khác nhau rõ ràng đối với bia giữa các khách hàng có độ tuổi khác nhau. Một số lý do có thể dẫn đến các kết luận ở trên. Người trẻ dễ chấp nhận thị hiếu và nhãn hiệu mới và sự trung thành với một nhãn hiệu của họ không cao so với những người khác. Trong khi các khách hàng cao tuổi có thể không thường uống bia ở Trung Quốc, họ cho thấy sự hài lòng tương đối thấp với bia. Người trung niên là nhóm tiêu dùng chính. Theo kết luận, sự khác nhau về sự hài lòng của khách hàng ở mức nào đó do thói quen tiêu dùng của các nhóm tuổi khác nhau gây ra. Công ty bia có thể cần nỗ lực nhiều hơn để khai thác thị trường người tiêu dùng trẻ.
Phụ lục D
(tham khảo)
Tỷ lệ các chi tiết không phù hợp của dây chuyền sản xuất7)
D.1 Nêu mục tiêu tổng thể
Trong một nhà máy, sản xuất bộ điều khiển điện tử, bốn dây chuyền sản xuất làm việc song song. Tỷ lệ các chi tiết khuyết tật đối với các đơn vị sản phẩm p nhận được là p ≈ 5 %. Giá trị đó cao không thể chấp nhận được đối với loại sản phẩm này và cần phải giảm trong khuôn khổ dự án Six Sigma.
Một trong những câu hỏi cần trả lời trong giai đoạn “Phân tích” là tỷ lệ của các sản phẩm khuyết tật có khác nhau giữa các dây chuyền hay không. Nếu có thì phân tích thêm sự khác nhau giữa dây chuyền kém hơn và dây chuyền tốt hơn có thể đưa đến nguyên nhân cho số chi tiết khuyết tật cao quan trắc được.
Giả định rằng có sự khác nhau về p giữa các dây chuyền. Để xác nhận, kiểm nghiệm c2 cho tính thuần nhất được áp dụng. Hiệu năng liên quan đến chất lượng đối với mỗi dây chuyền được ký hiệu là p1, p2, p3 và p4 cho tỷ lệ các chi tiết khuyết tật ở dây chuyền 1,2,3 và 4.
D.2 Liệt kê các thuộc tính quan tâm
Về thuộc tính đối với bảng chéo, hai biến phân loại được xem xét. Biến Y đại diện cho chất lượng với hai mức có thể: khuyết tật và không khuyết tật. Hai mức này loại trừ lẫn nhau. Biến X mô tả dây chuyền sản xuất với các mức 1,2,3 và 4. Đối với tất cả các tổ hợp của các mức X và Y, có thể tìm được tần số xuất hiện bằng cách ghi lại số sản phẩm kiểm soát có khuyết tật và không khuyết tật cho mỗi dây chuyền sản xuất trong khoảng thời gian nhất định. Nếu số đơn vị sản xuất trong mỗi dây chuyền được xác định là ni với i = 1..4 thì số đơn vị không khuyết tật trong dây chuyền i có thể được rút ra từ (ni - yi). Ở đây, yi đại diện cho số đơn vị khuyết tật của dây chuyền i. Các tham số p1, p2, p3 và p4 được ước lượng bằng cách chia tần số mức ‘khuyết tật’ của biến Y, yi cho số đơn vị sản xuất ni đối với mỗi mức i của biến X (dây chuyền).
D.3 Nêu giả thuyết không
Tỷ lệ các chi tiết khuyết tật đối với mỗi dây chuyền sản xuất p1, p2, p3 và p4 được coi là tham số phân bố của bốn phân bố nhị thức (cùng với các tham số tương ứng của cỡ mẫu ni i = 1, 2, 3, 4) của bốn tổng thể khác nhau.
Giả thuyết này bắt nguồn từ mục tiêu xác định xem các tham số p1, p2, p3 và p4 có khác nhau đáng kể hay không.
Hai giả thuyết bổ sung được xây dựng:
Giả thuyết không, H0: p1 = p2 = p3 = p4
Dây chuyền sản xuất có cùng tỷ lệ các đơn vị khuyết tật.
Đối giả thuyết, Ha: p1 ≠ pj i, j= 1, 2, 3, 4 với i≠j
Ít nhất một dây chuyền sản xuất có tỷ lệ đơn vị khuyết tật khác với một dây chuyền sản xuất khác.
Nếu H0 đúng, số quan trắc trong các ô của bảng chéo có phân bố thuần nhất trên dây chuyền theo tỷ lệ chung p1 = p2 = p3 = p4 và cỡ mẫu ni cho mỗi dây chuyền. Nói cách khác, không có mối quan hệ giữa biến Y (chất lượng theo phần trăm đơn vị khuyết tật) và biến X (các dây chuyền khác nhau).
D.4 Thiết kế phương án lấy mẫu cho nghiên cứu
Trong giai đoạn “Đo lường” của dự án Six Sigma đã được chứng minh (bằng cách sử dụng biểu đồ kiểm soát) là tỷ lệ các đơn vị sản phẩm khuyết tật không thay đổi đáng kể theo thời gian. Vì lý do đó giả định là về mặt chất lượng các quá trình trên mỗi dây chuyền sản xuất cũng ổn định.
Do đó, đối với nghiên cứu này, số đơn vị sản phẩm khuyết tật yi được ghi lại cho mỗi dây chuyền sản xuất trong khoảng thời gian xác định. Do thay đổi khối lượng công việc trên mỗi dây chuyền, tổng số đơn vị được sản xuất cũng được tính và đưa ra tổng số biên ni, i = 1..4. Số đơn vị không khuyết tật được tính theo (ni - yi) như đã đề cập trước đó.
Bảng D.1 trình bày bảng chéo và dữ liệu thu được để phân tích.
D.5 Dữ liệu thô
Dữ liệu được in đậm trong Bảng D.1 đã được ghi lại. Số đơn vị không khuyết tật đã được tính. Đối với cả hai biến X và Y, bảng chéo 4 x 2 đã được tạo ra và dữ liệu được điền đầy đủ
Bảng D.1 - Số sản phẩm khuyết tật và tốt của bốn dây chuyền sản xuất
Biến X | Biến Y “Chất lượng” | Ước lượng | ||
Đơn vị khuyết tật (yi) | Đơn vị không khuyết tật | Số đơn vị sản xuất | ||
Dây chuyền 1 | 10 | 117 | 127 | 0,079 |
Dây chuyền 2 | 12 | 144 | 156 | 0,077 |
Dây chuyền 3 | 7 | 133 | 140 | 0,050 |
Dây chuyền 4 | 4 | 253 | 257 | 0,016 |
D.6 Phân tích
So sánh tỷ lệ các chi tiết không phù hợp đòi hỏi sử dụng phân bố nhị thức rời rạc (khuyết tật/tốt) như được hiển thị bằng phần mềm (destra®8). Trong ví dụ hiện tại, bốn dây chuyền sản xuất được so sánh. Do đó, kiểm nghiệm c2 (thuần nhất) đối với nhiều hơn hai tổng thể được chọn (xem Hình D.1).
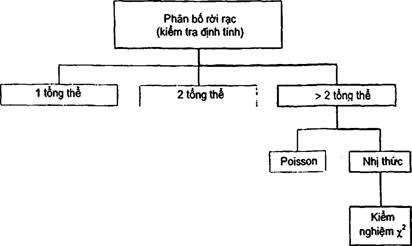
Hình D.1 - Lựa chọn hướng dẫn kiểm nghiệm c2 trong destra®
Kết quả kiểm nghiệm c2 trong destra® như sau.
Bảng D.2 - Kiểm nghiệm c2 trong destra®
| So sánh giá trị mong muốn của phân bố nhị thức | |||||||
| Kiểm nghiệm p (BD) k > 1 | |||||||
H0 | giá trị mong muốn của tổng thể bằng nhau | |||||||
Ha | giá trị mong muốn của tổng thể không bằng nhau (ít nhất đối với một cặp) | |||||||
Mức kiểm nghiệm | Giá trị tới hạn | Thống kê kiểm nghiệm | ||||||
Dưới | trên | |||||||
α = 5% | - | 7,81 |
| |||||
α = 1 % | - | 11,34 | ||||||
α = 0,1 % | - | 16,27 | ||||||
Kết quả kiểm nghiệm Bác bỏ giả thuyết không ở mức α ≤ 5 % |
| |||||||
Tổng thể | Hoạt động | Mô tả | n | x | Hệ số kiểm nghiệm (x) | Hệ số kiểm nghiệm (n-x) | ||
1 | X | Dây chuyền sản xuất 1 | 127 | 10 | 2,388 48 | 0,121 82 | ||
2 | X | Dây chuyền sản xuất 2 | 156 | 12 | 2,591 57 | 0,132 18 | ||
3 | X | Dây chuyền sản xuất 3 | 140 | 7 | 0,006 238 9 | 0,000 318 21 | ||
4 | X | Dây chuyền sản xuất 4 | 257 | 4 | 5,754 93 | 0,293 53 | ||
Phần cuối trong Bảng D.2 trình bày dữ liệu đối với dây chuyền sản xuất trong bốn hàng. Trong cột “x”, số đơn vị khuyết tật yi được đưa ra. Trong cột “n”, tổng số đơn vị được sản xuất ni được nhập theo dữ liệu thu được. Cột “Hệ số kiểm nghiệm (x)” và “Hệ số kiểm nghiệm (n-x)” cho thấy sự đóng góp với thống kê kiểm nghiệm c2. Điều này đề cập đến công thức được thể hiện trong lĩnh vực trên. Theo Công thức (2), với c = 2 và r = 4, công thức này bao gồm c = 2 số hạng, mỗi số hạng cho một cột trong bảng chéo [“Hệ số kiểm nghiệm (x)” cho số đơn vị khuyết tật và “Hệ số kiểm nghiệm (n-x)” cho số không khuyết tật]. Chỉ số l trong cả hai số hạng liên quan đến các tổng thể khác nhau l = 1.r và đề cập đến dây chuyền sản xuất i như được giới thiệu ở trên.
Giá trị mong muốn đối với số đơn vị khuyết tật được tính bằng ![]() cho mỗi dây chuyền sản xuất. Đối với các đơn vị không khuyết tật, là ni(1 -
cho mỗi dây chuyền sản xuất. Đối với các đơn vị không khuyết tật, là ni(1 -![]() ). Ở đây,
). Ở đây, ![]() là ước lượng đối với tỷ lệ chung p theo H0. Nó được tính bằng
là ước lượng đối với tỷ lệ chung p theo H0. Nó được tính bằng ![]() . Đối với dữ liệu cho trước,
. Đối với dữ liệu cho trước, ![]() = 0,048 5. Không có giá trị mong muốn nào trong ví dụ giảm xuống dưới 5. Do đó, xấp xỉ c2 của thống kê kiểm nghiệm được chấp nhận. Kết quả đối với thống kê kiểm nghiệm [là tổng trên các giá trị trong các cột “Hệ số kiểm nghiệm (x)” và “Hệ số kiểm nghiệm (n-x) là c2 = 11,289.
= 0,048 5. Không có giá trị mong muốn nào trong ví dụ giảm xuống dưới 5. Do đó, xấp xỉ c2 của thống kê kiểm nghiệm được chấp nhận. Kết quả đối với thống kê kiểm nghiệm [là tổng trên các giá trị trong các cột “Hệ số kiểm nghiệm (x)” và “Hệ số kiểm nghiệm (n-x) là c2 = 11,289.
Thay vì sử dụng p-giá trị, kết quả kiểm nghiệm cuối cùng được kết luận bằng cách so sánh giá trị c2 tính được tử c2 = 11,289 với giá trị c2 tới hạn của phân bố c2 cho xác suất α xác định cho sai lầm loại I xác định (và DF, bậc tự do có sẵn, DF = 3 trong ví dụ). Đối với tất cả các giá trị của thống kê kiểm nghiệm c2 lớn hơn phân vị tới hạn c21-α, DF, H0 bị bác bỏ (điều này sẽ xảy ra trong α % trường hợp, nếu H0 đúng). Phần trên bên trái trong Bảng D.2 cho thấy giá trị tới hạn đối với α = 5 %, 1 % và 0,1 %. Những giá trị này được chọn cho ba mức ý nghĩa trong việc bác bỏ H0. Kết quả so sánh và kết luận đối với ba giá trị α này được trình bày trong Bảng D.3.
Bảng D.3 - So sánh phân vị c2 tới hạn và thống kê kiểm nghiệm c2
Mức kiểm nghiệm | So sánh giá trị c2 và giá trị tới hạn | Kết luận | Mức ý nghĩa/hạng α | |
α = 5% | 11,289 > 7,81 | H0 bị bác bỏ | Có ý nghĩa* | 1 % < α ≤ 5 5 % |
α = 1 % | 11,289 < 11,34 | H0 không bị bác bỏ | Rất có ý nghĩa** | 0,1 % < α ≤ 1 % |
α = 0,1 % | 11,289 < 16,27 | H0 không bị bác bỏ | Có ý nghĩa cao*** | α ≤ 0,1 % |
p-giá trị tương ứng với kiểm nghiệm này là 0,010 27, gần với mức ý nghĩa 1 %. Ngoài ra, hệ số kiểm nghiệm trong Bảng D.1 (nghĩa là 2,388 48, 2,559 157, 0,006 238 9 và 5,754 93) cộng lại bằng 11,289 1 là giá trị thống kê kiểm nghiệm c2.
D.7 Kết luận
Từ Bảng D.3, như kết quả của việc bác bỏ H0 ở mức 5 %, sự chênh lệch trong tỷ lệ quan trắc của bốn dây chuyền sản xuất không thể được giải thích là do ngẫu nhiên. Có sự chênh lệch trong tỷ lệ các đơn vị khuyết tật giữa các dây chuyền sản xuất. Do đó, ít nhất hai dây chuyền có thể được so sánh trong một phân tích sâu hơn để xác định nguyên nhân tạo ra các đơn vị khuyết tật. Câu hỏi tiếp theo sẽ là: dây chuyền nào cần được so sánh?
Bảng D.2 thể hiện giá trị c2 lớn (5,75; 0,29) đối với dây chuyền sản xuất 4, nổi bật và dường như khác với các dây chuyền sản xuất còn lại.
Để kiểm nghiệm giả định này, cần tìm ra xem tỷ lệ các đơn vị khuyết tật giữa dây chuyền 1 đến 3 có khác nhau không mà không tính đến dây chuyền 4. Kiểm nghiệm được lặp lại mà không có dây chuyền 4.
Kết quả được trình bày trong Bảng D.4.
Bảng D.4 - Kiểm nghiệm c2 trong destra® mà không có dây chuyền 4
| So sánh giá trị mong muốn của phân bố nhị thức | |||||||
| Kiểm nghiệm p (BD) k > 1 | |||||||
H0 | giá trị mong muốn của tổng thể bằng nhau | |||||||
Ha | giá trị mong muốn của tổng thể không bằng nhau (ít nhất đối với một cặp) | |||||||
Mức kiểm nghiệm | Giá trị tới hạn | Thống kê kiểm nghiệm | ||||||
Dưới | trên | |||||||
α = 5% | - | 5,99 |
| |||||
α = 1 % | - | 9,21 | ||||||
α = 0,1 % | - | 13,82 | ||||||
Kết quả kiểm nghiệm Bác bỏ giả thuyết không. |
| |||||||
Tổng thể | Hoạt động | Mô tả | n | x | Hệ số kiểm nghiệm (x) | Hệ số kiểm nghiệm (n-x) | ||
1 | X | Dây chuyền sản xuất 1 | 127 | 10 | 0,192 06 | 0,014 136 | ||
2 | X | Dây chuyền sản xuất 2 | 156 | 12 | 0,159 23 | 0,011 720 | ||
3 | X | Dây chuyền sản xuất 3 | 140 | 7 | 0,703 28 | 0,051 764 | ||
4 | - | Dây chuyền sản xuất 4 | 257 | 4 | - | - | ||
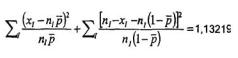
Từ Bảng D.4, có thể thấy giả thuyết không bị bác bỏ ở tất cả các mức kiểm nghiệm. Điều này cho thấy tỷ lệ các đơn vị khuyết tật đối với ba dây chuyền sản xuất đầu tiên là không khác nhau. Vì mức chất lượng của dây chuyền 4 tương đối tốt hơn mức chất lượng của ba dây chuyền kia, có thể kết luận rằng dây chuyền sản xuất 4 tạo ra số các đơn vị khuyết tật ít hơn các dây chuyền khác. Trong giai đoạn “Phân tích” của dự án Six Sigma mong muốn tạo cho dây chuyền sản xuất 1 đến 3 với mức hiệu năng như của dây chuyền 4.
Thư mục tài liệu tham khảo
[1] ISO 12888, Selected illustrations of gauge repeatability and reproducibility studies (Minh họa nghiên cứu độ lặp lại và độ tái lập đo)
[2] TCVN 8244-1:2010 (ISO 3534-1:2006), Thống kê học - Từ vựng và ký hiệu - Phần 1: Thuật ngữ chung về thống kê và thuật ngữ dùng trong xác suất
[3] TCVN 8244-2:2010 (ISO 3534-2:2006), Thống kê học - Từ vựng và ký hiệu - Phần 2: Thống kê ứng dụng
[4] ISO/TR 14468:2010, Selected illustrations of attribute agreement analysis (Minh họa phân tích tương đồng định tính)
[5] AGRESTI A.An Introduction to categorical data analysis: John wiley & sons, Inc, second edition, 2007 (Giới thiệu về phân tích dữ liệu phân loại)
[6] MINITAB. INC. Meet minatab 16. Available at: http://www.minitab.com/uploadedFiles/Sharedresources/documents/meetminitab/EN16 MeetMinitab.pdf
MỤC LỤC
Lời nói đầu
Lời giới thiệu
1 Phạm vi áp dụng
2 Tài liệu viện dẫn
3 Thuật ngữ và định nghĩa
4 Ký hiệu và chữ viết tắt
5 Mô tả chung về phân tích bảng chéo
5.1 Tổng quan về cấu trúc phân tích bảng chéo
5.2 Mục tiêu tổng thể của phân tích bảng chéo
5.3 Liệt kê thuộc tính quan tâm
5.4 Nêu giả thuyết không
5.5 Phương án lấy mẫu
5.6 Xử lý và phân tích dữ liệu
5.7 Kết luận
6 Mô tả phụ lục A đến phụ lục D
Phụ lục A (tham khảo) Phân bố một số vấn đề kỹ thuật được tìm thấy sau khi lưu hành sản phẩm vào lĩnh vực
Phụ lục B (tham khảo) Cảm nhận của con người về cuộc sống viên mãn
Phụ lục C (tham khảo) Nghiên cứu sự hài lòng của khách hàng về nhãn hiệu bia
Phụ lục D (tham khảo) Tỷ lệ các chi tiết không phù hợp của dây chuyền sản xuất
Thư mục tài liệu tham khảo
1) Six Sigma là nhãn hiệu thương mại của một sản phẩm do công ty Motorola cung cấp. Thông tin này được đưa ra để thuận lợi cho người sử dụng tiêu chuẩn này và không thiết lập sự xác nhận của sản phẩm được nêu tên. Các sản phẩm tương đương có thể được sử dụng nếu chúng cho thấy có thể dẫn đến các kết quả tương tự.
2) Nghiên cứu trường hợp này do Tiến sĩ Michèle Boulanger, công ty JlSC-Statistics cung cấp.
3) Nghiên cứu trường hợp này do Tiến sĩ Avinash Dharmadhikari, công ty ô tô Tata cung cấp.
4) Minitab là tên thương mại của một sản phẩm do công ty Minitab cung cấp. Thông tin này được đưa ra để thuận tiện cho những người sử dụng tiêu chuẩn này và không thiết lập sự xác nhận của sản phẩm được nêu tên. Có thể sử dụng các sản phẩm tương đương nếu chúng cho thấy có thể dẫn đến các kết quả tương tự.
5) Nghiên cứu tình huống này do Bà Jian Kang, Viện Tiêu chuẩn Quốc gia Trung Quốc cung cấp.
6) SAS là tên thương mại của một sản phẩm do công ty SAS cung cấp. Thông tin này được đưa ra để thuận tiện cho những người sử dụng tiêu chuẩn này và không thiết lập sự xác nhận của sản phẩm được nêu tên. Có thể sử dụng các sản phẩm tương đương nếu chúng cho thấy có thể dẫn đến các kết quả tương tự.
7) Nghiên cứu trường hợp này do ông René Pleul, công ty trách nhiệm hữu hạn Tư vấn và Đào tạo TEQ cung cấp.
8) destra® là nhãn hiệu của một sản phẩm do công ty trách nhiệm hữu hạn phần mềm Destra cung cấp. Thông tin này được đưa ra đề thuận tiện cho những người sử dụng tiêu chuẩn này và không thiết lập sự xác nhận của sản phẩm được nêu tên. Có thể sử dụng các sản phẩm tương đương nếu chúng cho thấy có thể dẫn đến các kết quả tương tự.
